Power Query は Excel や Power BI Desktop で利用する機能です。そして、この機能を使うときに起動して利用するのが Power Query エディターです。
Power Query エディターは、データ ソースからデータを抽出 (Extract) して、必要なら変換 / 加工 (Transform) して、適切な場所に書き出す (Load) 機能をもっている ETL ツールという分類のツールです。
つい最近、これを VBA で処理するにはどうしたらよいかと聞かれたので、そちらをPower Query を使って対応する例でご紹介します。
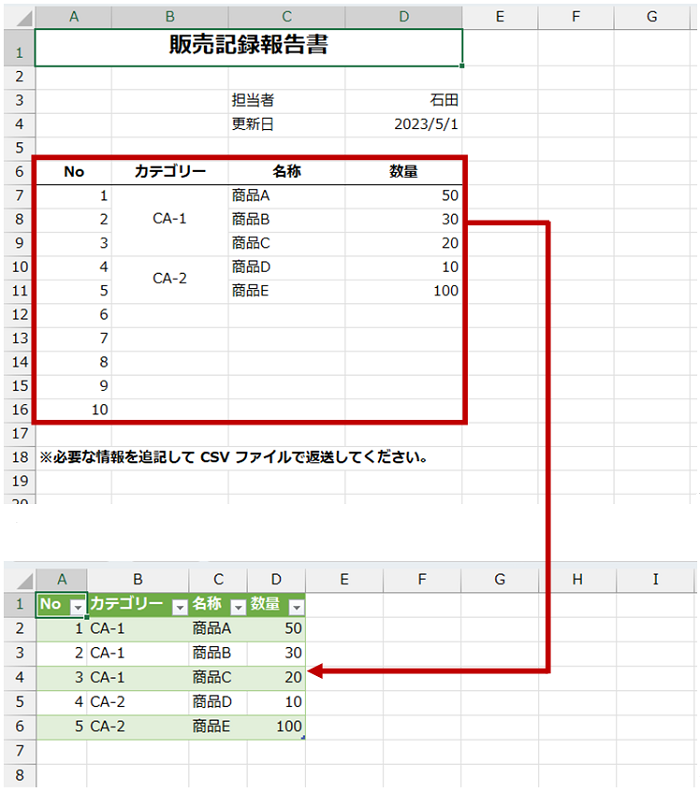
定期的に入手する図のような定形の Excel ワークシート (データ ソース) があるとします。
保存場所はデスクトップの [Data] フォルダー、ファイル名は File1.xlsx、シート名は Sheet1 です。
このワークシートの 6 行目から 16 行目の商品名のある行を抽出して、セル結合されている部分をなんとかするなどの加工をし、ワークシートに書き出してテーブルにしたい、このときに Power Query を使います。
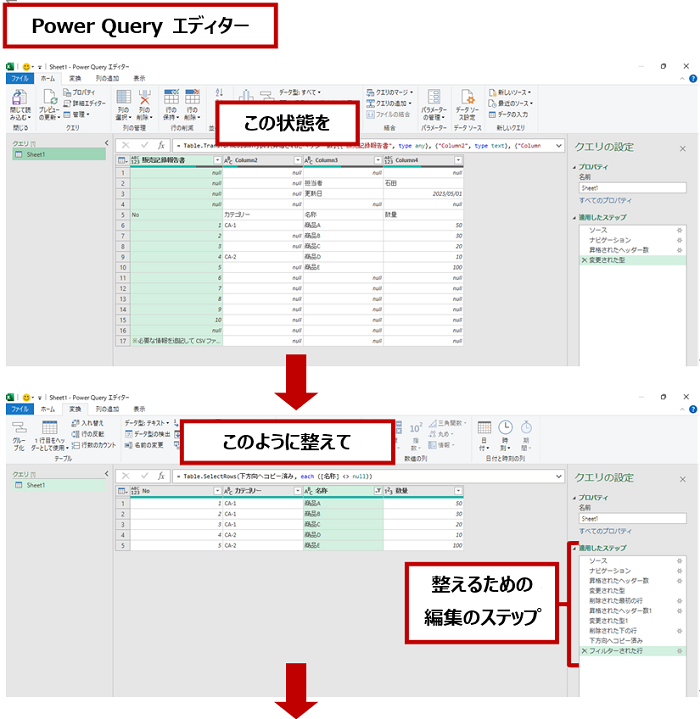
特徴的なのは、基本的にはマウスなどによる GUI 操作でこれらの処理をステップ化して記録できることです。
また、どんな形に整えてからワークシートに書き出したいのか、そのためにどんな順番でどんな処理をしたらよいのかをステップ化しておくことで、最初は面倒なこともあるかもしれないけれど、次回以降は同じ名前 / 構造のファイルを同じ場所に配置すれば、更新を実行するだけで最新の結果を書き出すことができます。
ETL ツールである Power Query エディター自体はデータ自体を保管する場所ではありません。データの抽出と加工、書き出しをするためのツールです。
ワークシートなどに書き出した結果が料理 (集計作業やレポート化など) を開始できる状態の食材だとするならば、Power Query エディターは食材を切ったり、扱いやすいように並べたり、要らない部分を取り除くなどの作業をするときに使う、いわば下ごしらえの段階を担当するツールということです。
今後少しずつ書いていきますが、今回は上記の例でご紹介したステップを実際の画面つきで少し解説してみます。
雰囲気をみていただくための手順なのであまり細かいことは書いていませんし、やっていることもとても軽いです。実際にはできることがもっともっともーっとありますよ。
ここでは、データ ソースとなるファイル (File1.xlsx) とは別に、集計用.xlsx というブックを用意しました。
テーブルとしてデータを書き出したいブックです。
- データを書き出したいブックのリボンの [データ] タブの [データの取得と変換] グループの [データの取得] をクリックし、[ファイルから] - [Excel ブックから] をクリックします。
もちろんデータ ソースとなるファイルが CSV ファイルなら [テキストまたは CSV から] を選びます。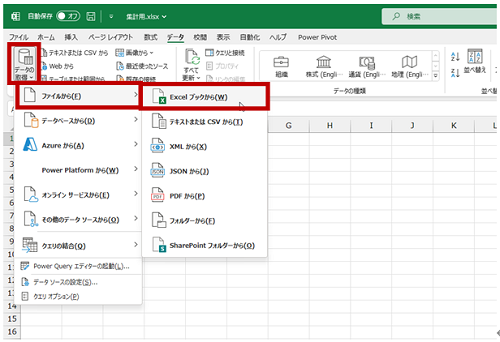
- [データの取り込み] ダイアログ ボックスでデータ ソース (File1.xlsx) を選択して [インポート] を実行します。
ここで選択した場所やファイル名は特別なことをしなければ固定されます。だから更新作業だけで対応できるようになるのです。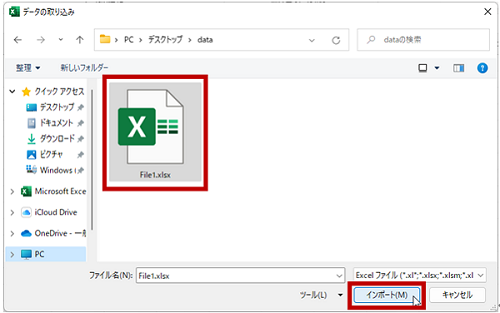
- [ナビゲーター] ウィンドウが表示され、左上に選択したファイル名が表示されます。今回のようにデータ ソースが Excel ブックの場合はブック内のワークシートやテーブルの名前が表示され、どの部分を読み込みたいのかを選択して(Power Query エディターで変換 / 加工するため) [データの変換] をクリックします。
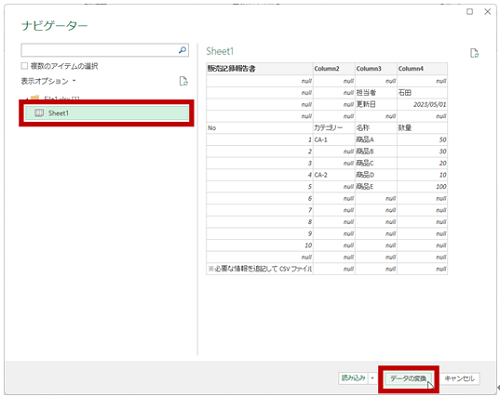
- Power Query エディターが起動し、選択したデータ ソースの名前が付けられたクエリ (接続) が準備されます。
このとき、中央に表示されているテーブルは、右側に表示されている最後のステップまでが適用された状態で、もし今ワークシートへの書き出しを行ったら、この状態のテーブルが作成されます。
ユーザーはファイルを指定しただけで特別なことは行っていませんが、データの特徴などから自動的に適用された 4 つのステップが [適用したステップ] に表示されています。(たとえば、ワークシートの先頭にあった文字列が見出しに昇格されているなど)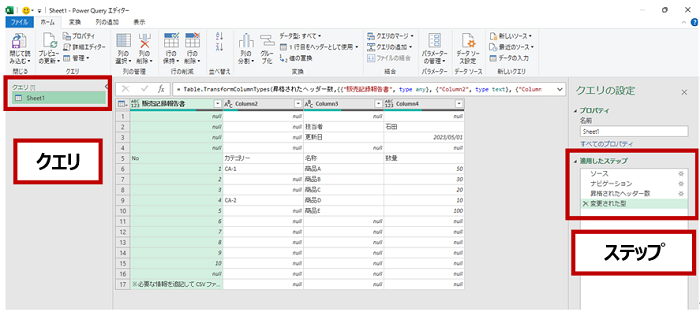
- テーブルには不要な 1 ~ 4 行目を削除します。
Excel の感覚だと 1 ~ 4 行目を選択して削除を実行するのですが、データ ソースとして指定されたワークシートの上から 4 行削除する、としています。(データ ソースを別のブックに差し替えて更新したとき毎回必ず上から 4 行が削除されます。)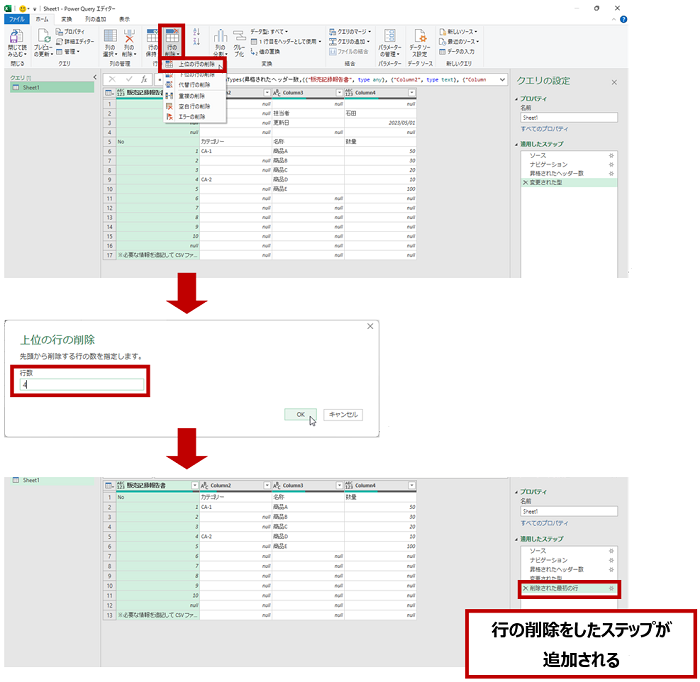
- 現在の 1 行目を列の見出し (ヘッダー) とするために [1 行目をヘッダーとして使用] を実行しています。
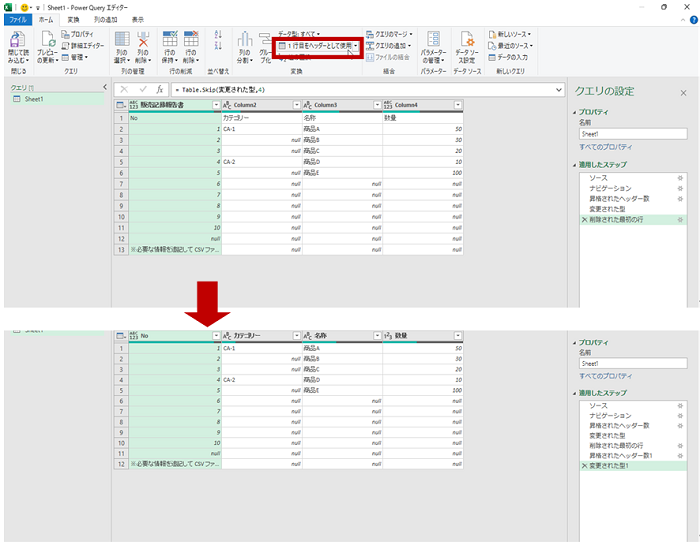
- テーブルには不要な 11 ~ 12 行目を削除します。
こちらもデータ ソースとして指定されたワークシートの下からから 2 行削除する、としています。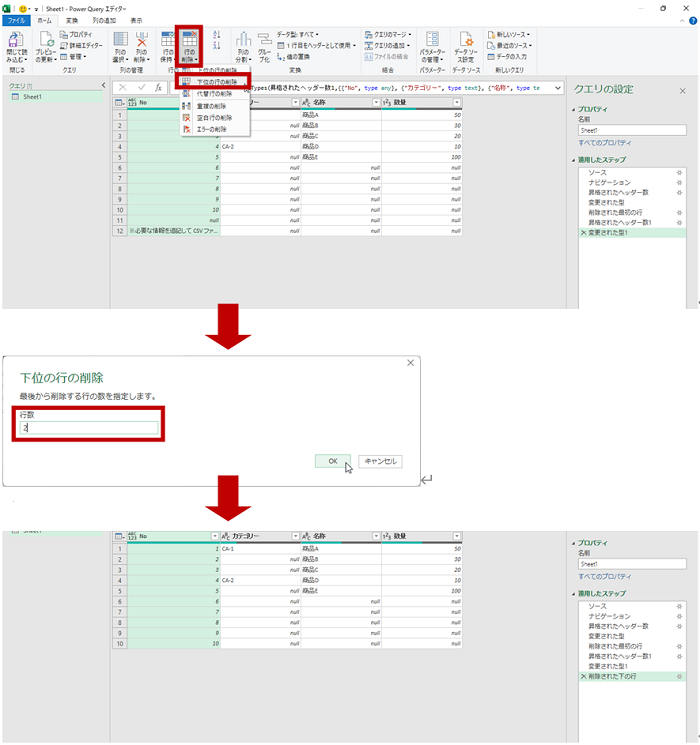
- [カテゴリー] 列は、ワークシート上でセルが結合されていたため該当する範囲の先頭にのみ値があり、それ以外は null になっています。
フィル (コピー) を実行して、null の上部にある値をコピーして上書きし、[カテゴリー] 列のすべての行に該当するカテゴリーが格納されるようにしています。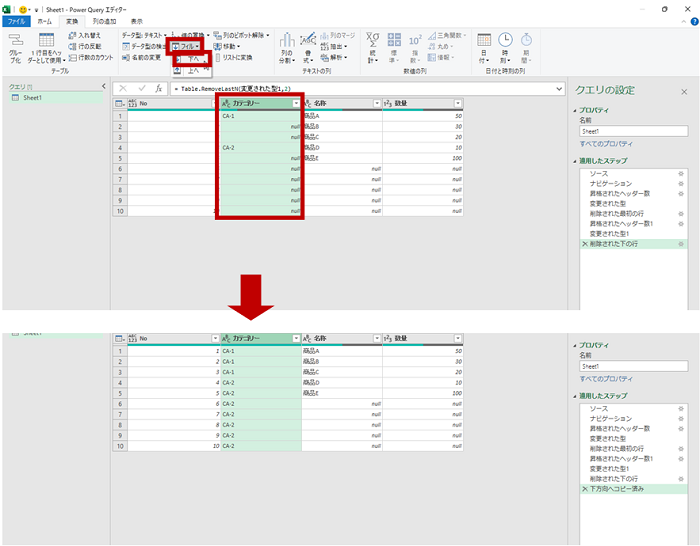
- [名称] 列が null、すなわちデータのない行は除外するため、[名称] 列でフィルターを実行しています。
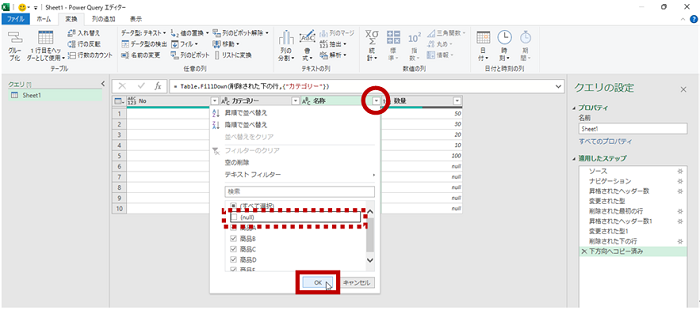
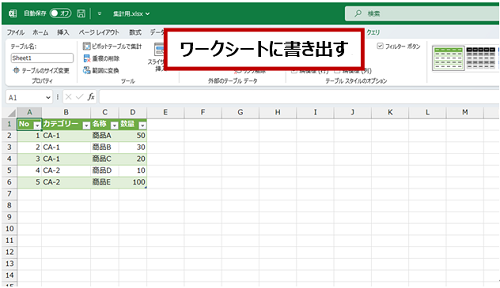
- ワークシートに書き出したい形に整いました。
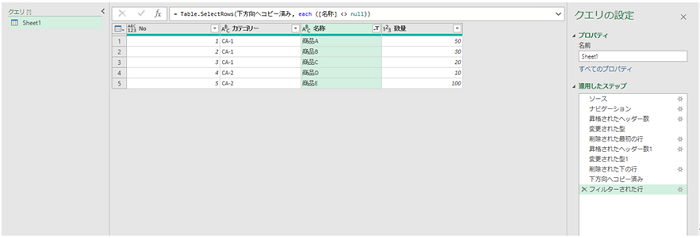
- 既存のワークシートにテーブルとして結果を書き出します。
[閉じて読み込む] を実行すると新しいワークシートにテーブルが作成されるので、[閉じて次に読み込む] を実行してテーブルとして表示するワークシートとセルを指定しています。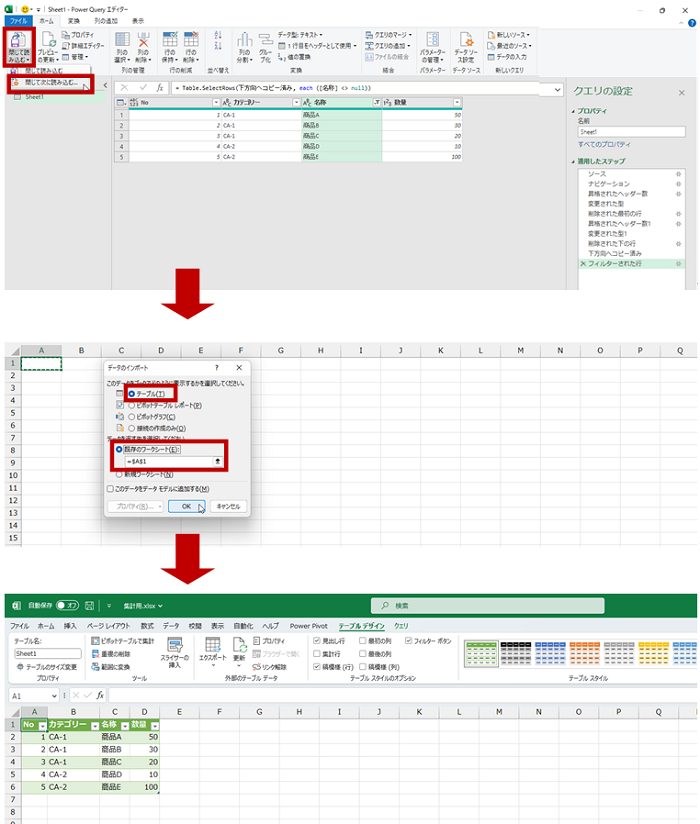
ここ↓までくれば、足りない列を追加して計算するなり、ピボットテーブルで集計するなり、CSV ファイルとして保存するなり、なんでもできますね。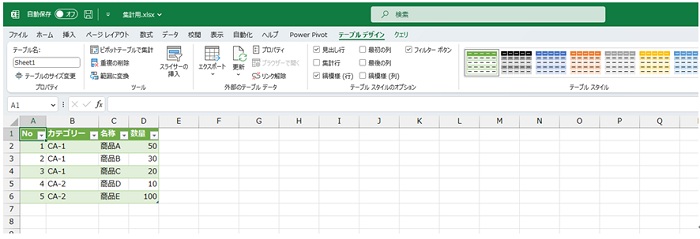
同じファイル名でファイル構造も同じだけれど、格納されているデータの異なるブックを用意しました。
イメージは最新のファイルが送られてきたから更新したテーブルを作りたい、というところでしょうか。
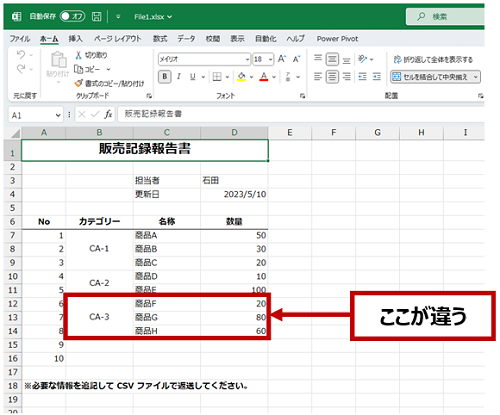
このブックを最初のブックが保存されていた場所 (デスクトップの [Data] フォルダー) に格納して更新を実行するだけで追加されたデータも含めて最新の結果がテーブルに反映されます。
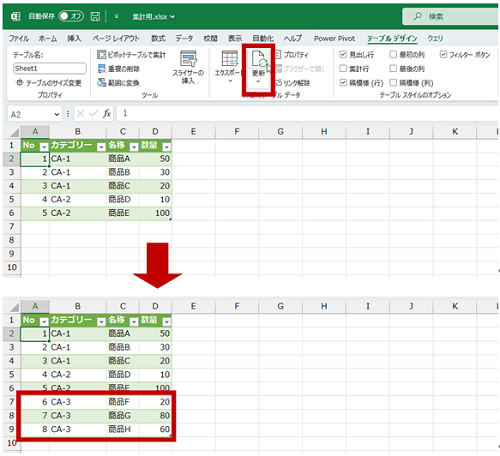
今回のようなケースでは、手動で不要なセルを削除してセル結合を解除することもできるでしょうし、また、マクロを作成して処理することが苦ではない方もいらっしゃるでしょう。それがだめだとはいっていないです。
Power Query を使ってどんな形に整えてからワークシートにインポートするのかを決めておき、同じ構造のファイルを同じ場所に配置すれば、更新を実行するだけで最新の状態を手に入れられる、そのような準備しておくことも選択肢の 1 つということです。
繰り返し行われる作業、特に元データを加工して整えて集計などを行いたいというときに、これからは Power Query を普通に使えて当たり前になってくるかもしれません。少しずつ具体的なこともご紹介していきたいと思います。
石田 かのこ








